INTRODUCTION
The information provided within this article was taken from a peer-reviewed article entitled, "Machine learning and dyslexia: Classification of individual structural neuro-imaging scans of students with and without dyslexia."
The aim of the research was to determine if machine learning could be used as a viable method for identifying dyslexia and other disabilities.
The World Health Organization defines dyslexia as a specific reading disorder characterized by a specific and significant impairment in the development of reading skills that are unrelated to problems with visual acuity, schooling or overall mental development.
Presently, dyslexia is diagnosed using behavioral analysis by professionals with many years of education in identifying and classifying dyslexia. For obvious reasons, this means some who suffer from dyslexia may not be diagnosed as dyslexic early in their education. Late identification of the condition could have a detrimental effect on their education.
A better classification system is required to identify dyslexia; one that is both widely available, easy to use and reliable. One such device or tool for classification is machine learning.
By using multivariate classification techniques with machine learning other disorders such as depression have been successfully identified with accuracy rates as high as 90%. Extending this type of diagnosis tool to dyslexia would be a breakthrough for science and vastly improve the lives of those who suffer from dyslexia.
Therefore, this study looks at the possibility of correctly classifying those with and those without dyslexia using bio markers such as physical differences in brain matter (BM). Support vector machine (SVM) and cross-validation are the machine learning tools used to quantify and analyze data.
METHODOLOGY
Two groups were selected. The first group consisted of 49 students: 22 students with a diagnosis of dyslexia and 27 students without dyslexia. This group was comprised of 1st year psychology students who spoke native Dutch. Students in this group completed at least 12 years of education.
The second group consisted of 876 subjects from the general population: 60 with a reported diagnosis of dyslexia and 816 with no reported history of dyslexia. Education attainment levels varied. IQ among this group was expected to be lower than that of group 1.
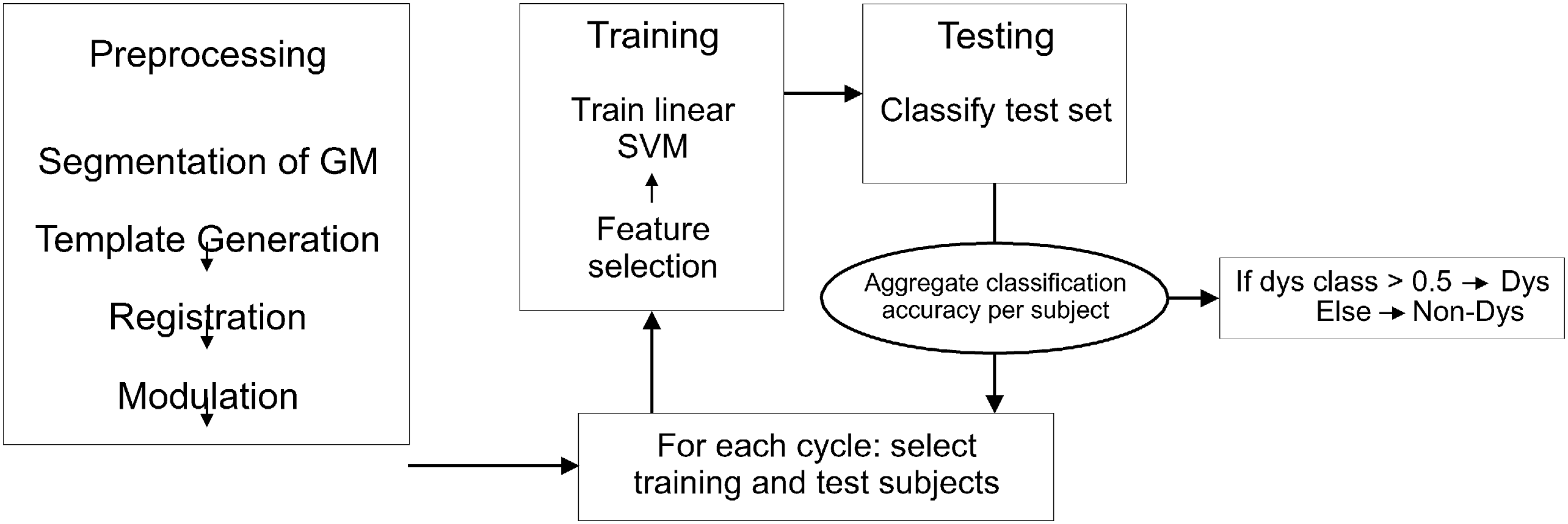
A support vector machine (SVM) was used to train a classifier to identify dyslexia using a voxel based morphometry (VBM).
VBM involves a voxelwise comparison of regional gray matter 'density' between two groups of subjects. The classifier was trained by using 21 subjects with and 21 subjects without dyslexia. Figure 1 show a visual interpretation of the classification scheme.
RESULTS
Outcomes for Group 1:
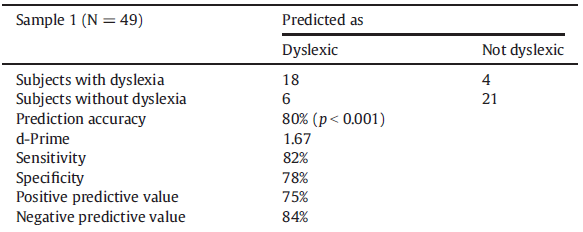
The SVM technique accurately predicted the presence of dyslexia in 80% of the students.
See Table 1 for the results of Group 1 and the outcomes for mean classification accuracy.
With regards to morphological differences (anatomic classification) in brain structures for both dyslexic and non-dyslexic subjects, Figure 2 makes some interesting, albeit statistically not relevant, observations.
The blue region (LIPL) is smaller in subjects with dyslexia and the regions in red (LOFG and ROFG) are larger in subjects with dyslexia. The 3rd side image or view of the brain represents the portion of the brain where these regions are found.

- severity of dyslexia correlates significantly with gray matter (GM) volume in the ROFG and LOFG
- good performance in spelling correlates significantly negative with GM volume in the LOFG and significantly positive with GM volume in the LIPL
- good performance in whole-word-reading correlates significantly negative with GM volume in the LOFG
- good performance in phonology correlates significantly positive with GM volume in the LIPL
Outcomes for Group 2:
The anatomical classifier of Group 2 resulted in a predictive accuracy of 59%.
Table 2 shows the results.
This lower predictive value for Group 2 couldn't be explained when selecting subjects by similar ages and sex compared with Group 1. It was however evident that the lower classification accuracy was mostly due to false alarms.

CONCLUSION
Using SVM to classify those with and without dyslexia and their severity can be somewhat accurately predicted. The prediction is not without errors and is not currently at the level of accuracy required for clinical use.
In the case of this study we would have predictions for dyslexia where dyslexia does not exist.
Tamboer, P., Vorst H. C., Ghebreab S. & Scholte H. S. (2016). Machine learning and dyslexia: Classification of individual structural neuro-imaging scans of students with and without dyslexia. NeuroImage: Clinical, 11, 508-514. https://doi.org/10.1016/j.nicl.2016.03.014
Of interest, when analyzing the anatomical classifier we can conclude the LOFG is an important area in dyslexia. Overall, different types of dyslexia are characterized by different combinations of anatomy and functionality. This outcome makes dyslexia classification complex and nuanced.
Dyslexia does not appear to be a uniform disorder. Further multivariate analysis must be made with additional variables (biomarkers) in hopes to improve the significance of correlation. More clearly stated, we don't currently have the full picture of dyslexia and its component parts.
For the purposes of brevity we summarized the results of this study and in so doing omitted much of the analysis. If you would like to read this study in further detail we will cite the source.